
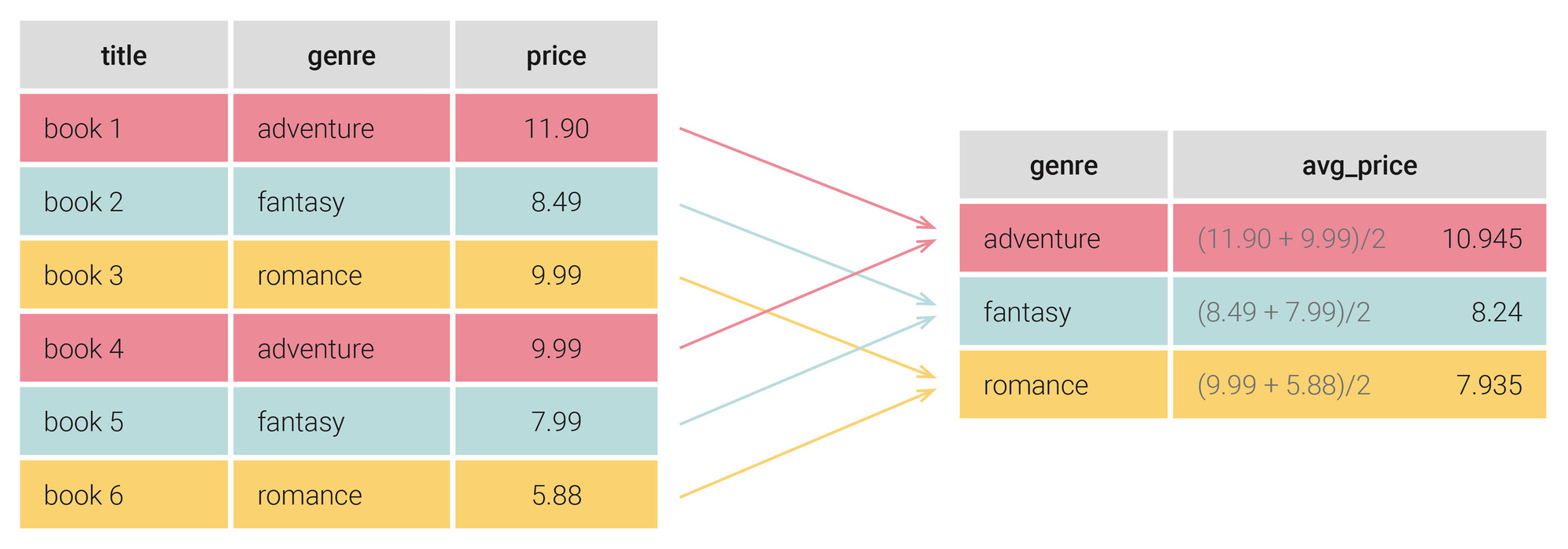
データベースに眠る膨大なデータは、適切な分析によって初めて価値を生み出します。SQLのGROUP BY句は、データをグループ化し、集計することで、データの背後に隠されたパターンやトレンドを明らかにするための強力な武器となります。
さらに、本稿では、GROUP BY句の基本概念から、複雑な集計分析、パフォーマンス最適化、高度な応用までを徹底的に解説します。特に、データ分析のプロフェッショナルを目指す方に向けて、実践的なノウハウを提供します。
また、SQL初心者向けの基本構文解説やデータベース設計の基本も併せてご覧ください。
1. GROUP BY句の核心:データのグループ化と集計
GROUP BY句は、SELECT文と組み合わせて使用されます。具体的には、指定された列の値が同一の行をグループ化し、グループごとに集計関数(COUNT、SUM、AVG、MAX、MINなど)を適用することで、グループごとの集計結果を生成します。
1-1. 基本構文と機能
CopySELECT 列名1, 集計関数(列名2)
FROM テーブル名
GROUP BY 列名1;
重要なポイント:
- GROUP BY句は、指定された列の値に基づいて行をグループ化します
- 各グループに対して集計関数を適用します
- データの分布、傾向、異常値などを把握することが可能となります
1-2. 具体的な使用例
顧客ごとの注文回数を集計する場合:
CopySELECT customer_id, COUNT(*) AS order_count
FROM orders
GROUP BY customer_id;
商品ごとの売上合計を集計する場合:
CopySELECT product_id, SUM(price * quantity) AS total_sales
FROM orders
GROUP BY product_id;
つまり、これらの例では、データを特定の基準でグループ化し、そのグループごとに統計値を算出しています。
2. GROUP BY句の多角的活用:高度な集計分析への展開
一方で、GROUP BY句は、複数の列でのグループ化、HAVING句との組み合わせ、サブクエリとの連携など、様々な方法で拡張することができます。
2-1. 複数列でのグループ化:多次元分析の実現
顧客ごと、商品ごとの注文回数を集計する例:
CopySELECT customer_id, product_id, COUNT(*) AS order_count
FROM orders
GROUP BY customer_id, product_id;
メリット:
- より細かい粒度でのグループ化が可能
- 多次元的な分析が実現
- 複雑なビジネス要件に対応
2-2. HAVING句による集計結果のフィルタリング
HAVING句は、GROUP BY句でグループ化された後の集計結果に対して条件を指定するために使用します。
注文回数が3回以上の顧客を抽出する場合:
CopySELECT customer_id, COUNT(*) AS order_count
FROM orders
GROUP BY customer_id
HAVING COUNT(*) >= 3;
WHERE句とHAVING句の違い:
- WHERE句:グループ化前の行に対して条件を指定
- HAVING句:グループ化後の集計結果に対して条件を指定
2-3. サブクエリとの連携:複雑な集計分析とデータ抽出
サブクエリとGROUP BY句を組み合わせることで、より複雑な集計分析や、集計結果に基づくデータの抽出が可能となります。
顧客ごとの平均注文金額よりも注文金額が高い注文を抽出する場合:
CopySELECT *
FROM orders o1
WHERE price > (
SELECT AVG(price)
FROM orders o2
WHERE o2.customer_id = o1.customer_id
);
3. GROUP BY句の性能最適化:大規模データ処理への挑戦
大規模なデータセットに対してGROUP BY句を使用する場合、パフォーマンスが課題となることがあります。そこで、以下の最適化戦略を検討してください。
3-1. インデックスの戦略的活用
GROUP BY句で使用する列に適切なインデックスを作成することで、グループ化の処理速度を大幅に向上させることができます。
具体的な効果:
- データ検索速度の向上
- ソート処理の効率化
- メモリ使用量の削減
3-2. データ型の選択と最適化
不要な文字列型の使用を避け、適切なデータ型を選択することで、データサイズを削減し、パフォーマンスを向上させることができます。
推奨事項:
- 数値データには適切な数値型を使用
- 文字列長の最適化
- 不要な精度の回避
3-3. クエリ構造の見直しと最適化
不要な列の選択や複雑な条件指定は、パフォーマンス低下の原因となります。したがって、クエリの構造を見直し、最適化することで、効率的なデータ抽出が可能となります。
4. GROUP BY句の高度な応用:データ分析の可能性を拡張
4-1. ウィンドウ関数との協調:高度な集計分析
ウィンドウ関数とGROUP BY句を組み合わせることで、グループごとの累積集計や移動平均など、より高度な集計分析が可能となります。
顧客ごとの累積注文金額を算出する場合:
CopySELECT customer_id, order_date,
SUM(price) OVER (PARTITION BY customer_id ORDER BY order_date) AS cumulative_sales
FROM orders;
利点:
- 時系列データの分析が可能
- トレンド分析の実現
- 複雑な計算ロジックの簡素化
4-2. 共通テーブル式(CTE)との連携:複雑なクエリの構造化
共通テーブル式(CTE)とGROUP BY句を組み合わせることで、複雑なクエリを構造化し、可読性と保守性を向上させることができます。
実用的な例:
- 段階的な集計処理
- 中間結果の再利用
- クエリの構造化
5. まとめ:GROUP BY句の極致とデータ分析の未来
結論として、GROUP BY句は、単なるグループ化と集計に留まらず、高度なデータ分析を可能にする多機能なツールです。さらに、パフォーマンス最適化と高度な活用法を組み合わせることで、データ分析の精度と効率を飛躍的に向上させることができます。
次のステップ:
- 実際のデータセットでの練習
- 複雑なクエリの構築
- パフォーマンスチューニングの実践
そして、本稿で得た知識を基に、GROUP BY句を駆使し、データから未知の洞察を引き出し、データ分析の新たな地平を切り拓いてください。
参考リンク: